Understanding Self-Supervised Learning
Exploring the fundamentals, methodologies, and applications of self-supervised learning, a technique revolutionizing AI by leveraging unlabeled data for representation learning.
Table of Contents
- Introduction
- The Problem
- Self-Supervised Learning Techniques
- Experimental Methodology
- Implementation Details
- Results and Analysis
- Conclusion
- Project Report
- Further Reading
Introduction
Self-Supervised Learning (SSL) is transforming the landscape of artificial intelligence by enabling models to learn from vast amounts of unlabeled data. Unlike traditional supervised learning, which relies on labeled datasets, SSL formulates pretext tasks to extract meaningful representations from raw data. This technique is widely used in computer vision and natural language processing, underpinning state-of-the-art models like GPT, BERT, and Vision Transformers (ViTs).
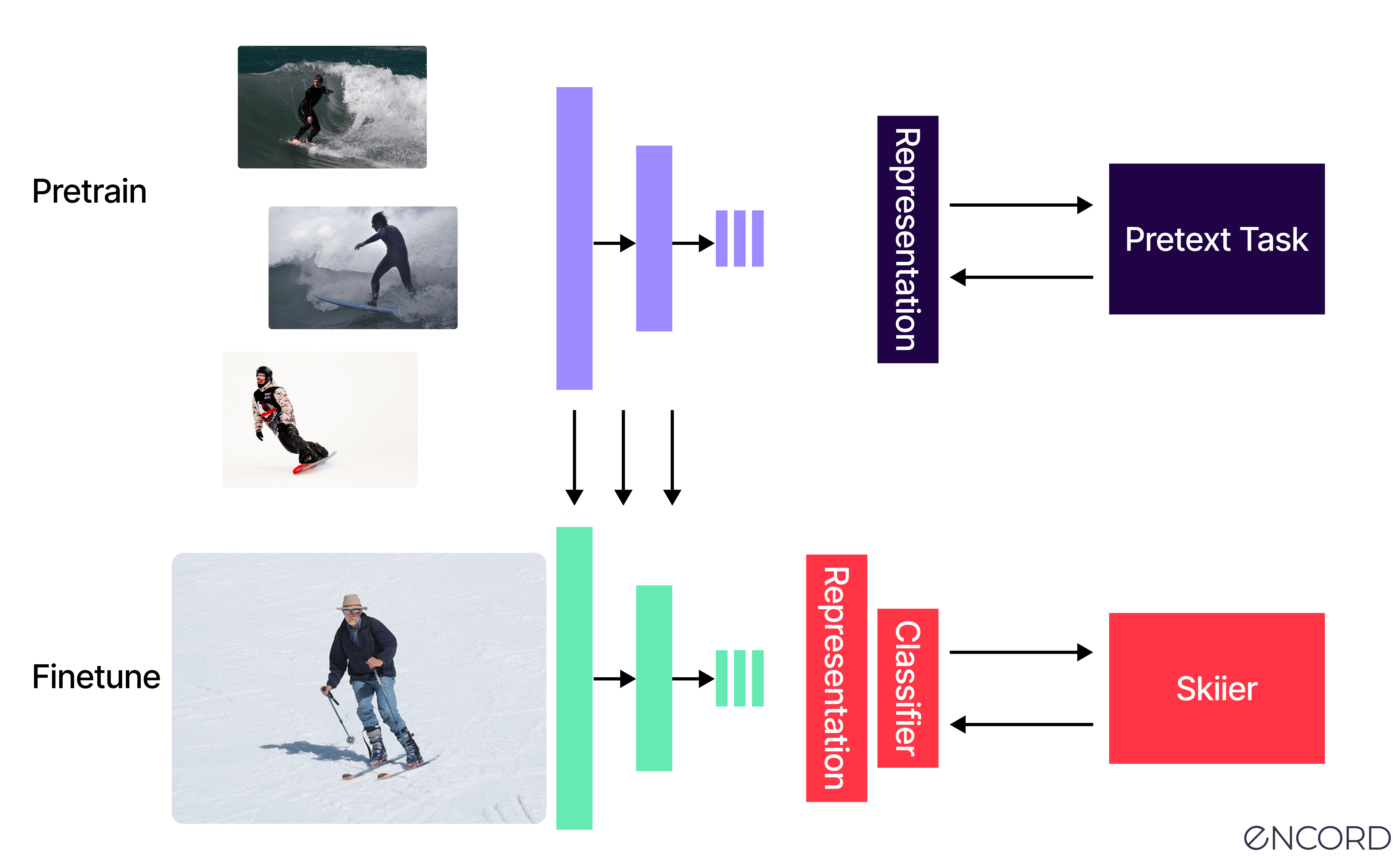
The Problem
The primary challenge in machine learning is the dependency on large labeled datasets, which are expensive and time-consuming to annotate. SSL mitigates this issue by allowing models to generate pseudo-labels through structured learning tasks. In real-world scenarios such as healthcare, autonomous vehicles, and recommendation systems, SSL proves invaluable by reducing the reliance on manually annotated data while preserving model performance.
Self-Supervised Learning Techniques
Pretext Tasks
Pretext tasks in SSL are designed to provide supervision without explicit labels. Some common techniques include:
- Image Rotation Prediction: The model classifies the degree of rotation applied to an image (0°, 90°, 180°, 270°).
- Contrastive Learning: Learning representations by maximizing agreement between similar data points while pushing apart dissimilar ones (e.g., SimCLR, MoCo).
- Masked Token Prediction: Used in NLP, where the model predicts missing words in a sentence (e.g., BERT).
- Jigsaw Puzzle Solving: Shuffling image patches and training the model to reconstruct the original order.
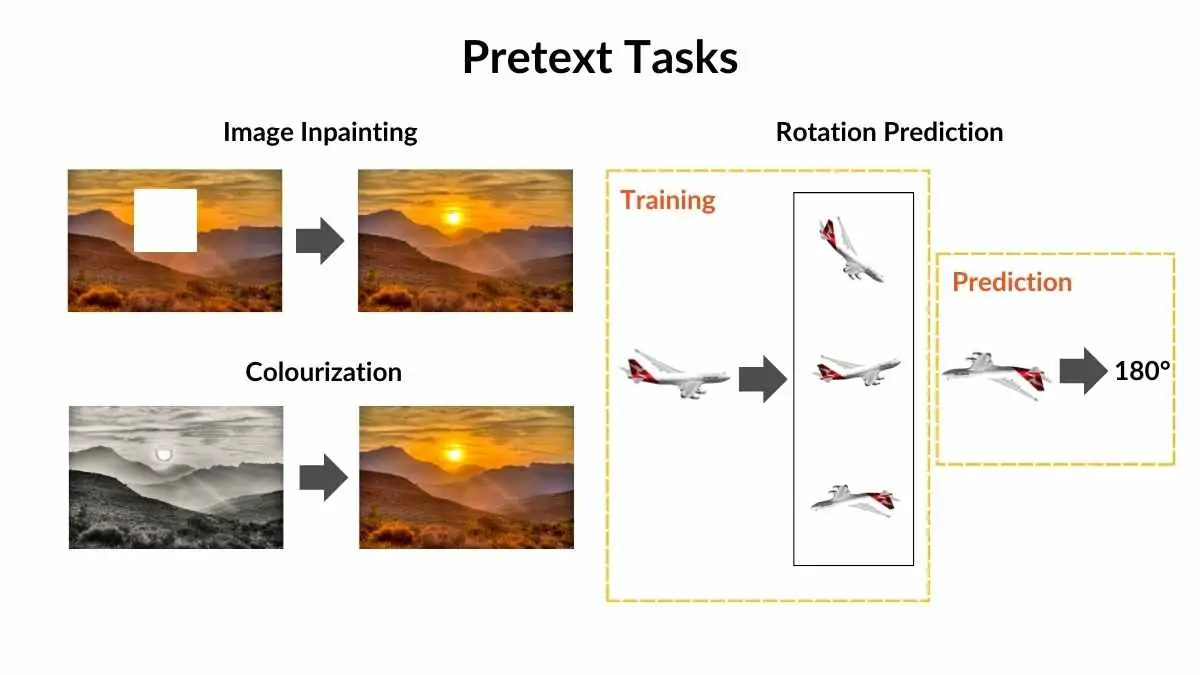
Advantages and Limitations
Advantages:
- Drastically reduces dependency on labeled data.
- Yields transferable representations for various downstream tasks.
- Enables learning from large-scale, uncurated datasets.
Limitations:
- The effectiveness of learned representations is highly dependent on pretext task selection.
- Computationally expensive, requiring extensive resources.
- May not generalize well across all domains without proper tuning.
Experimental Methodology
To demonstrate SSL in action, we designed an experiment using the Tiny ImageNet dataset. The experiment involved training a model on a rotation prediction pretext task before fine-tuning it on a downstream image classification task (distinguishing between “Duck” and “Fish” classes).
Dataset:
- 100,000 training images, 10,000 validation images, 10,000 test images.
- Images resized to 64x64 pixels.
- Objects span diverse categories, making it ideal for feature learning.

Model Architecture:
- Feature Extractor: MobileNetV2 was used to extract meaningful representations.
- Pretext Task Head: A fully connected layer predicting rotation angles.
- Downstream Task Classifier: Fine-tuned on a subset of labeled images.
Results and Analysis
Performance of SSL Model
Baseline Model (Trained from Scratch):
- Struggled with convergence, yielding poor generalization.
- High variance in validation accuracy.
SSL Model (Using MobileNetV2 Feature Extractor):
- Achieved superior convergence and stability.
- Fine-tuned classifier showed robust generalization on unseen data.
Key Takeaways:
- Feature extractors pre-trained via SSL significantly enhance performance.
- Rotation-based pretext tasks effectively capture structural information in images.
- Fine-tuning allows rapid adaptation to downstream tasks with minimal labeled data.
Conclusion
Self-supervised learning is revolutionizing the way AI models learn from data. By leveraging unlabeled datasets, SSL minimizes reliance on manual annotations while delivering state-of-the-art results. From NLP to computer vision and beyond, SSL is poised to play a crucial role in future AI advancements. As research in this domain progresses, more sophisticated pretext tasks and training methodologies will unlock new frontiers in machine learning.
Would you like to explore self-supervised learning further? Check out the resources below!
Project Report
You can view the full report below:
If the embedded view does not work, you can download the report here.
Further Reading
- YouTube, “Self-Supervised Learning Overview,” available at: YouTube.
- Neptune.ai, “Self-Supervised Learning: What It Is and How It Works,” available at: Neptune.ai.
- V7 Labs, “The Ultimate Guide to Self-Supervised Learning,” available at: V7 Labs.
- Shelf.io, “Self-Supervised Learning Harnesses the Power of Unlabeled Data,” available at: Shelf.io.
- Kaggle, “Tiny ImageNet,” available at: Kaggle.
- Tsang, S., “Review: SimCLR – A Simple Framework for Contrastive Learning of Visual Representations,” available at: Medium.
- AI Multiple, “Self-Supervised Learning,” available at: AI Multiple.
GitHub Repository
Check out the implementation and source code on GitHub:
Self-Supervised Learning Repository.